Archive
Author Archive
Azure Data Factory : “Failure on Sink side – Cannot find object because it doesn’t exist or you do not have permissions”
May 3, 2024
Leave a comment
Sometimes in ADF, you’ll try to write to a newly created table, using the same Linked Service connection you have used previously for the database. You might this strange error above, where it says that you don’t have permissions to write to that table.
Just grant access again to that specific table ( I know, it should have it if it has DB access ).
GRANT ALTER, INSERT, SELECT ON dbo.tblTableName TO user_name;
Should do the trick …….
Categories: Azure
Power BI – Maps not displaying the correct location.
April 17, 2024
Leave a comment
Here’s a common issue with potentially an easy fix (depending on your geography).
You have location data in your dataset, but when Power BI displays it on a map, it gets it all wrong. This looks especially bad, for some reason, when using Q and A. In the image below you’ll see that for the state WA representing “Western Australia”, Power BI actually plots this to WA in the USA ( Washington State ).
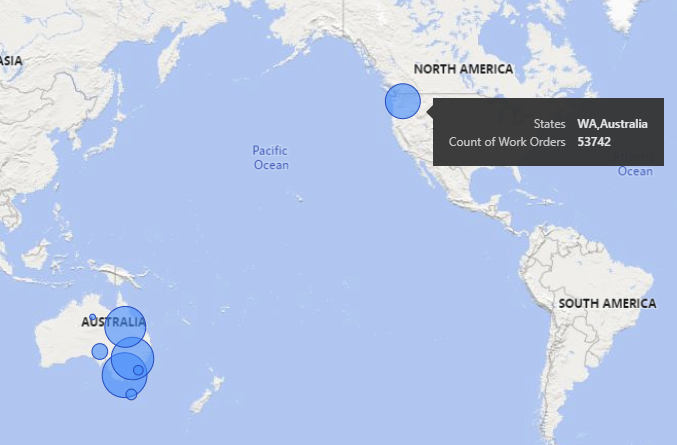
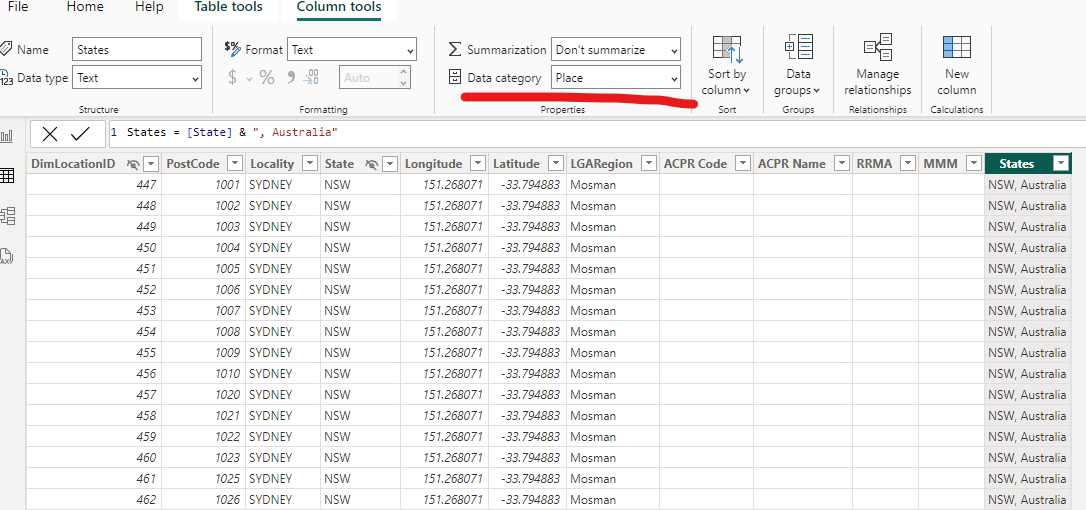
Now you can try and update the data field to include the country name, ( ie. “WA, Australia ), and that solves it some cases but not for my report. What I had to ALSO do was also go to the Table View, select the column ( in this case my new column with the country name – the old one was hidden ) and at the top, change the Data Category to “Place”.
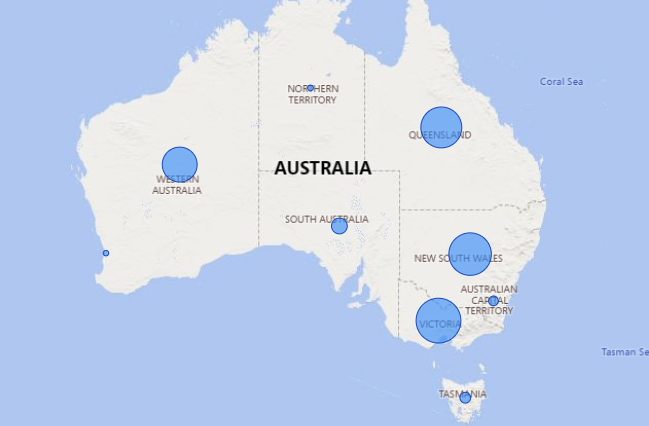
After doing that, it works !
Categories: Power BI
Azure Data Factory – Invalid Template, The ‘runAfter’ property of template action contains non-existent action
November 7, 2023
Leave a comment
Quick post. Some of you might be building ADF pipelines and getting an error like the above. You won’t believe how simple this one is. Lets say your pipeline looks like the below :
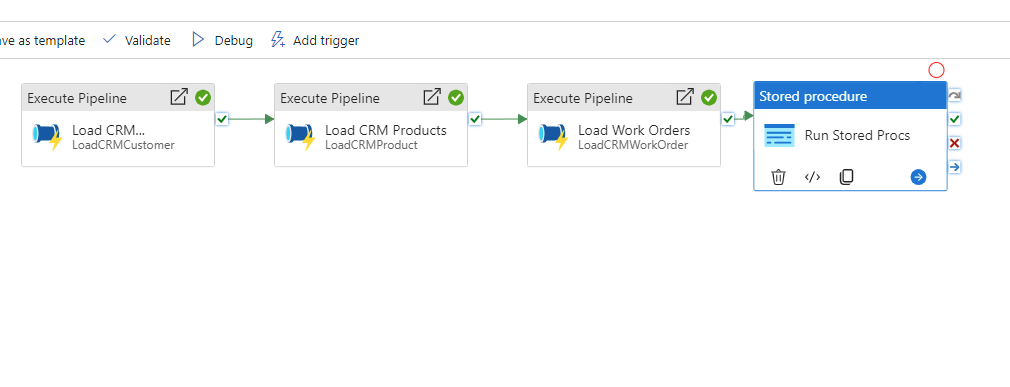
The Pipeline is not running and complaining about the ‘runAfter’ property. Sometimes this happens if the Name of the previous block has a space after it. So in the above, we go to the properties of Block 3, “Load Work Orders”
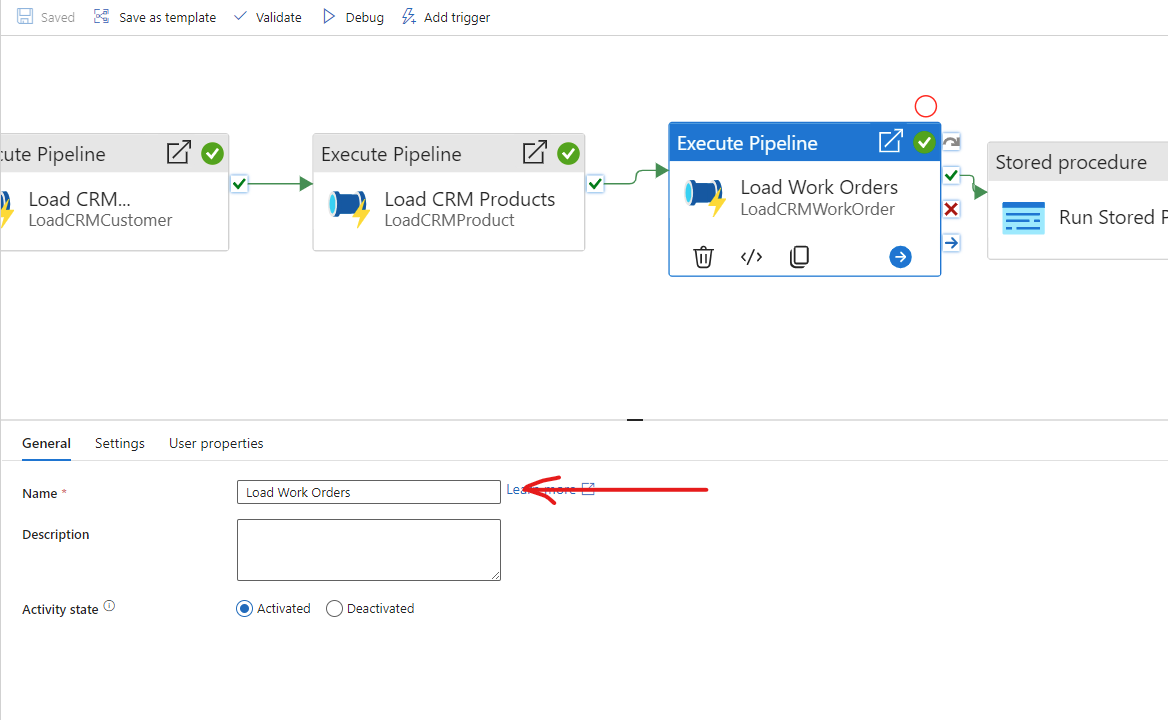
Just make sure there isn’t a space after the name.
Categories: Azure
From Text Prediction to Conscious Machines: Could GPT Models Become AGIs ?
April 4, 2023
Leave a comment

Image via http://www.vpnsrus.com
Picture this : a world where AI is not just a “chatbot” you interact with , but an entity that is responsible for decision making, scientific research and even guiding humanity.
Welcome to the world of AGIs, Artificial General Intelligence, which refers to AI systems as smart as humans, or greater. The quest for AGI has been a long-standing goal of the AI community, and recent advances in generative models have led to an increasing interest in their potential for achieving AGI.
Generative Models
A generative model is a type of machine learning model that is able to generate data samples, based on the large volumes of data that it is trained on (mostly text but now increasing images as well). They can learn the patterns and structures of language from a large corpus of text and then generate new text that is coherent and follows the same patterns.
The breakthrough here was to use “Transformers” – a type of neural network introduced in 2017.
Now, more interestingly ……I asked GPT whether a Generative Model could generate something that was never in its training data ( important as we move to AGIs ). Here was its response:

The answer is that, by identifying patterns and data structure, it may be able to, but will struggle to generate anything vastly different from the training data, and nothing “completely novel”. This is where we are currently.
A mirror into your civilization
If I had to describe GPT in an exciting way :
Currently, Generative Models are a mirror of your civilization at a point in time, an automated and efficient record and reflection of everything you have done ( once trained on everything )
Given that humans have to generate science, art and culture over many years, and then train the models on the entirety of this, there is a huge dependency – for these Generative models to have any value, the content on which the model is trained needs to be created first.
These models may seem “smarter” than a human, but that is because they can access information generated by human culture and civilization instantly, whereas the humans, whose creativity came up with everything in the first place, cannot.
The Two Planets example
To further illustrate, I have come up with the “two planets” example.

In this scenario, imagine a duplicate civilization that has evolved to the same level as the Earth-Human civilization, say on Proxima Centauri. They would potentially have similar cultural achievements, and the same level of technology, although their language, appearance, etc could be different. At the same time as Earth, they develop Generative models and their version of GPT4.
If we queried the Earth GPT4 model about anything on Proxima Centauri, it would know nothing...
Of course, the reciprocal would apply as well. Even a more advanced model, a GPT 5 or 6, would have the same limitations, as it was not trained on any data from that planet. Would you still consider it “intelligence” ?
How useful would GPT be in this scenario? Well, if the aliens came here, they could use the Earth GPT4 to learn all about our planet, culture and achievements, assuming they quickly learned one of our languages that the GPT model is also familiar with. However, what was once being spoken of as an “AGI” may not be considered as such in this example.
What would be truly impressive is if the Earth GPT4 could understand images or pass an IQ test from the hypothetical Proxima Centauri civilization….
Innate Intelligence
It is still amazing to me that GPT4 has an understanding of patterns, relationships in images, and the ability to pass a simple IQ test. Yes, it was trained by its creators to do this, based on data of mankind’s history, but once trained it has this ability.

This brings us to the definition of Intelligence itself, and the concept of innate intelligence.
“Every living being has some level of innate intelligence”
While factors such as education, socioeconomic status, and cultural experiences can impact cognitive development and, in turn, influence IQ test performance in humans, these are not the only factors that influence intelligence. Genetics, neurological factors, and individual differences in learning capability also play a role. Therefore, there is an innate intelligence in every living being that plays a large part in the resulting visible intelligence demonstrated in the real world.
How do we create an artificial intelligence with some level of innate intelligence ?
Remember, if a human baby grows up in a culture different to his/her parents, learning a different language, the child still manages to learn quickly.
Consider this – if we go back to the Two Planets example, and we are confident that while the Earth GPT4 will have no knowledge of culture, language, events etc from another civilization, but that it WILL manage to :
- Perform mathematical calculations that are constant in the universe
- Understand basic patterns that are constant in the universe
- Learn the basic structures of language that may be common in the universe
- Thus, ….have the ability to potentially learn from ANOTHER civilization and their data
We then approach something very exciting…… we could then argue that in creating these models which, admittedly had to be trained on all our data to start with, we are taking the first steps into creating something with a small amount of innate intelligence. And each subsequent model would then build on the previous in terms of capability, until….well, would iteration 7 or 8 be an AGI ?
Are they AGIs ?
At this point we need to be clear on what our definition of an AGI is, as we are finally moving in the direction closer to creating one. I believe that our definition has become muddied.
Does an AGI and the Singularity simply refer to any intelligence smarter than humans ?
If we go back to the 1993 definition of the Singularity, as per the book “The Coming Technological Singularity” by Vernor Vinge, he spoke of “computers with super-human intelligence”. I could argue that GPT4 already is smarter than any human in terms of recalling knowledge, although it would be less capable in creativity, understanding and emotional intelligence.
He also talks about human civilization evolving to merge with this super intelligence. This hasn’t happened but brain interfaces have been built already. A brain interface into Chat GPT4 that would allow a human to call up all our civilizations knowledge instantly, turning him/her into a “super human”, is actually possible with today’s technology. It could be argued then that we have met the criterion already for the singularity by the 1993 definition……
The Singularity
If we move to futurist Ray Kurzweils definition of the Singularity, he spoke of “…when technological progress will accelerate so rapidly that it will lead to profound changes in human civilization…”.
Here, the year 2023 will certainly go down as the start of this change. The year 2013, due to the emergence of GPT3 and then GPT4, is a watershed year in technological history, like the launch of the PC or the internet.
Already there are conversations that I can only have with GPT4 that I cannot have with anyone else. The reason is that the humans around my may now be knowledgeable on particular topics, so I turn to GPT4. I sometimes do try to argue with it and present my opinion, and it responds with a counter argument.
By our previous definition of what an AGI could be, it can be argued that we have already achieved it or are very close with GPT4.
We are now certainly on the road to AGI, but we now have to clearly define a roadmap for it. This isn’t binary anymore, as in something is either an AGI or not. More importantly, the fear mongering around AGIs will certainly not apply to all levels of AGI, once we clearly define these levels.
This is particularly important, as recently people such as Elon Musk have publicly called for a “pause” in the development of AGIs as they could be dangerous. While this is correct, this will also rob humanity of the great benefits that AIs will bring to society.
Surely if we create a roadmap for AGIs and identify which level would be dangerous and which will not, we could then proceed with the early levels while using more caution on the more advanced levels ?
The AGI Roadmap
Below is a potential roadmap for AGIs with clearly defined stages.
Level 1: Intelligent Machines – Intelligent machines can perform specific tasks at human-level or better, such as playing chess or diagnosing diseases. They can quickly access the total corpus of humanity’s scientific and cultural achievements and answer questions. Are we here already ?
Level 2: Adaptive Minds – AGIs that can learn and adapt to new situations, improving their performance over time through experience and feedback. These would be similar to GPT4 but continue learning quickly post training.
Level 3: Creative Geniuses – AGIs capable of generating original and valuable ideas, whether in science, art, or business. These AGIs build on the scientific and cultural achievements of humans. They start giving us different perspectives on science and the universe.
Level 4: Empathic Companions – AGIs that can understand and respond to human emotions and needs, becoming trusted companions and helpers in daily life. This is the start of “emotion” in these intelligent models, however by this time they may be more than just models but start replicating the brain in electronic form.
Level 5: Conscious Thinkers – AGIs that have subjective experiences, a sense of self, and the ability to reason about their own thoughts and feelings. This is where AGIs could get really unpredictable and potentially dangerous.
Level 6: Universal Minds – AGIs that vastly surpass human intelligence in every aspect, with capabilities that we cannot fully define yet with our limited knowledge. These AGIs are what I imagined years ago, AGIs that could improve on our civilizations limitations, and derive the most efficient and advanced designs for just about anything based on the base principles of physics ( ie. Operating at the highest level of knowledge in the universe).
As you can see, levels 1-3 may not pose much of a physical threat to humanity, while offering numerous benefits to society, therefore we could make an argument for continuing to develop this capability.
Levels 4-6 could pose a significant threat to humanity. It is my view that any work on a level 4-6 AGI should be performed on a space station on Moon base, to limit potential destruction on Earth. It is debatable whether the human civilization would be able to create a Level 6 AGI, even after 1000 years…
Universal Minds
Over the last few decades, I have been fascinated with the concept of an Advanced AGI, once that is more advanced than humans and that could thus rapidly expand our technological capability if we utilize it properly.
Here is an old blog post on my Blog from 2007 where I was speculating on the Singularity being near, after following people like Kurzweil.
What I always imagined was a “super intelligence” that understood the universe from base principles much better than we did, even if it was something we created. Imagine an intelligence that, once it gets to a certain point, facilitates its own growth exponentially. It would perform its own research and learning.
It would be logical that such an intelligence plays a role in the research function of humanity going forward.
It could take the knowledge given to it and develop scientific theory far more effectively than humans. Already today, for example, we see a lot of data used in Reinforcement Learning being simulated and generated by AI itself. And if the total data we have is limiting, we could then ask it to design better data collection tools for us, ie. Better telescopes, spacecraft, and quantum devices.
A simple example that I would use would be the computing infrastructure that we use, on which everything else is built.
Most computers today use what’s known as the “Von Neumann” architecture, which is shown below. The main drawback of this architecture is that data has to be constantly moved between CPU and memory, which causes latency.
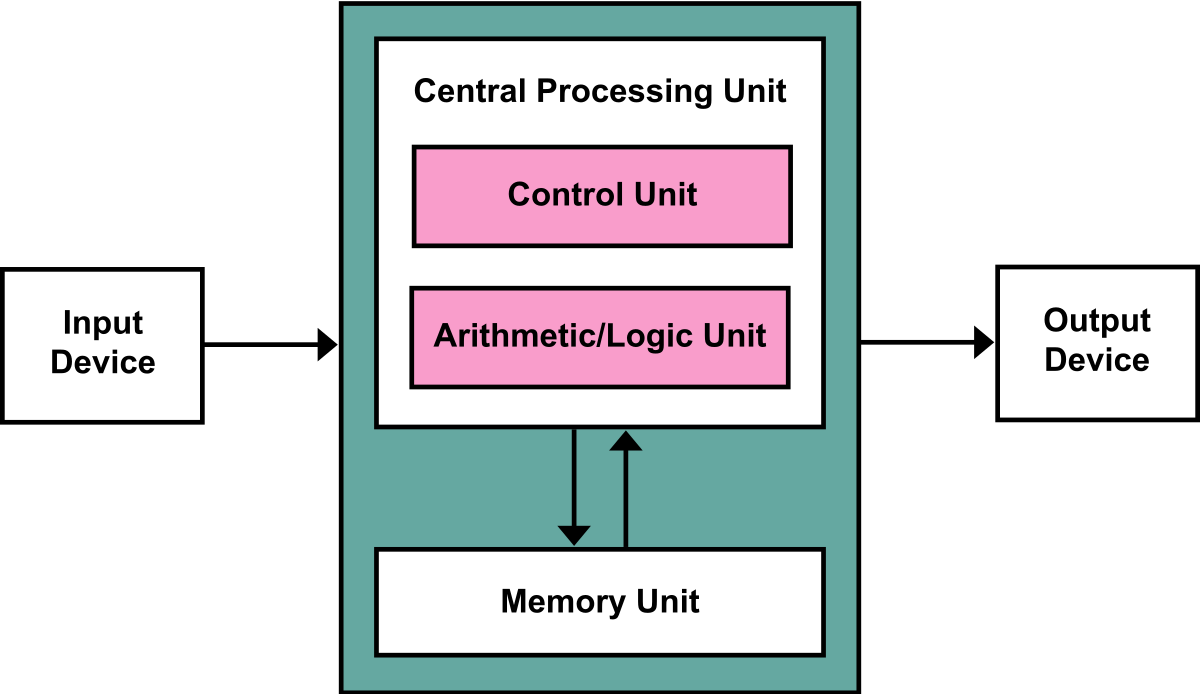
On top of this we typically use the x86 CPU, then Operating systems like Windows or Linux, then applications written in programming languages like C++.
Imagine if we could engineer an optimal, efficient computing architecture, from base principles, with orders of magnitude improvements at base architecture level, CPU level, OS level and application software level. This would be a difficult task for humans to undertake today, not just in terms of the actual technical design, but also in building it, and to collaborate on the next layer above, and to adopt the technology.
With a “super-intelligent” Universal AI, it would have the power to generate every layer at once.
It would also give us design schematics for the factories to build the new components, that too in the most quickest and efficient way.

Summary
Hold on to your seats ! …..
Some GPT models have already shown an impressive ability to pass IQ tests and learn basic mathematics, hinting at the potential for developing a level of intelligence that goes beyond simple text generation. Now that we have an example of a roadmap for AGIs ( above ), we can certainly see how GPT is the start of the early phases in this roadmap, although more technical breakthroughs will be needed to eventually get to the later stages.
So buckle up and get ready – We don’t know where the end of this road is and where it will take us, but with GPT models now mainstream, we now know that as of 2023 we are at least on the road itself, travelling forward.
Appendix
Below is a great video that I found explaining what Transformers are:
Categories: AI
AI, Artificial Intelligence, Machine Learning
Power BI “Horizontal Fusion”
September 28, 2022
Leave a comment
It’s been awhile since we had a snazzy tech term which promises amazing performance gains… (remember “Heckaton” and “Vertipaq”…),
…but here’s something to bring back the old glory days….the impressively named “Horizontal Fusion“.
Now this one seems to be an engine improvement in Power BI, specifically as to how it creates DAX queries against your source, and with noticeable performance improvements especially in DirectQuery mode. The best part is that you enable it and it works in the background.
Once that’s done you should see fewer, more efficient DAX queries generated against your sources. Apparently it even works with Snowflake.

This is the type of new feature I like, one where I don’t have to do anything….
More information here : https://powerbi.microsoft.com/en-us/blog/announcing-horizontal-fusion-a-query-performance-optimization-in-power-bi-and-analysis-services/
Categories: Uncategorized
Delivering AI in Banking
June 17, 2022
Leave a comment
I recently interviewed Paul Morley, Data Exec at NEDBANK, on implementing Big Data and AI in Banking. Hope you enjoy it !
Categories: AI
Intro to Quantum Computing
March 30, 2021
Leave a comment
I interview Kimara Naicker, PHD in Physics and researcher at the University of Natal, and we discuss the basics of Quantum Physics and Computing.
Categories: Uncategorized
Windows 10 – cannot adjust brightness / screen dim
November 19, 2020
Leave a comment
Quick tip – I had this annoying behaviour on my main laptop where suddenly the screen was too dim and I couldn’t adjust the brightness.
There are many solutions on the internet including :
- Updating drivers
- Adjusting display settings in your power profile.
None of that worked for me. What I DID find was that on the Display screen , just under the brightness setting , you may see an option for “HDR”. For some reason this was set to “On” on my machine – simply turning it off restored the brightness to the display.
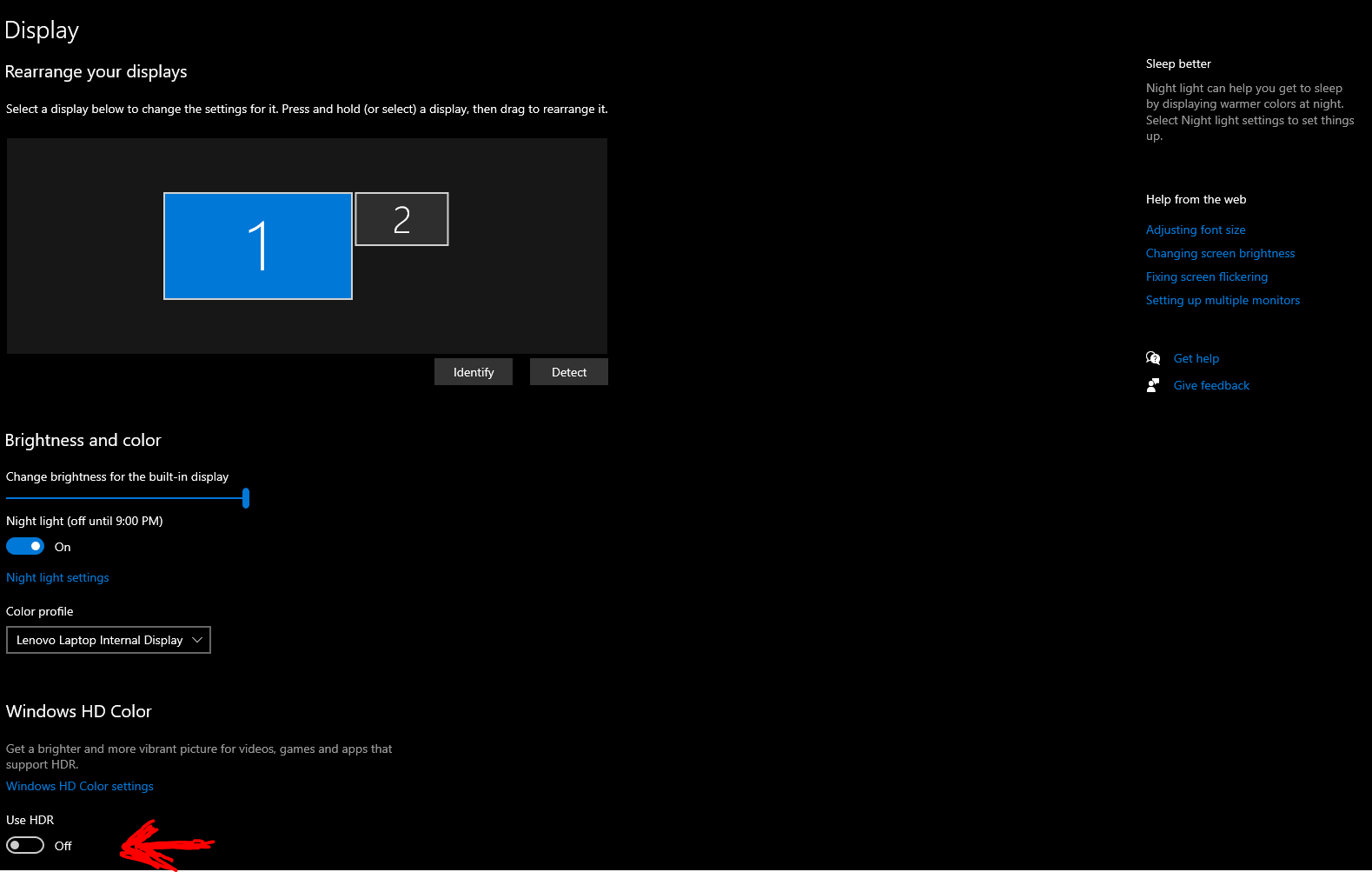
Categories: Uncategorized
Simplifying ML with AZURE
October 30, 2020
Leave a comment
Here’s the Azure ML walkthrough you’ve been waiting for. In 30 mins I take you through a broad overview with demos of the 3 main areas of Azure ML. Enjoy.
Categories: AI, Azure
AIIOT; Azure; Sphere; ML; Microsoft, Azure, Microsoft
The state of AI
September 16, 2020
Leave a comment
Recently at AI EXPO AFRICA 2020, I was interviewed by Dr Nick Bradshaw, where we had a quick chat on the current state of AI. I shared my thoughts on the progress I’ve seen over the last 2-3 years , but also some of the challenges facing us in the future. These include :
- Education – while AI will definitely have an impact on certain types of jobs in the future, corporations and governments need to make education accessible ( and cheaper ) to move people up the value chain. Countries that do this will enable their populace to enter new fields in the job market that crop up – countries that don’t will suffer tremendously. I will explore the impact of AI to jobs from an economic perspective in an upcoming article.
- Use cases – Until recently, technologists were struggling to find business buy in for Machine Learning use cases. While this has improved , I proposed the Microsoft “4 pilar” of digital transformation as a guideline for developing these use cases.

When you focus on problem areas , like how do we improve the customer experience, or how do we make internal operations more efficient, you will develop use cases for ML that are measureable in their value to business.
Lastly , I also mentioned that the penetration of AI will continue to happen very swiftly and transparently. I spoke of how microcontrollers / CPUs slowly spread across equipment / cars / appliances in the 20th century, bringing simple logic to those devices and improving operations. Consider when cars moved to electronic engine management systems – you now could build in simple IF-THEN-ELSE decisions into software that was running the engine , leading to more efficient operation.
Now, we see ML models being deployed everywhere , assisted by ML capable hardware ( ie. neural network engines in CPUs for example ). An example I used was my phone unlocking by seeing my face – there is a neural network chip onboard , which is running software with a trained model on it. This progress happened seamlessly, all most consumers knew was that their new model phone could do this without knowing all of the above. And so it will continue……
The video is below :
Categories: AI
AI, Artificial Intelligence, Machine Learning, ML
